-
분산 학습과 집합 통신AI/distributed 2022. 5. 29. 13:39
안녕하세요~
오늘은 분산학습이 등장하게 된 배경과 정의 그리고 실제 분산학습에서 Gradient 전달을 위한 통신 흐름을 소개해보고자 합니다.
개인적으로 작년에 분산학습이 무엇인지 빠르게 배우고 적용해보는 시간들이 많았습니다만.. 올해 들어 그런 기회가 없어 블로그로 제가 배웠던 내용들을 한곳에 모아보려고 합니다. 소개해보려는 순서는 다음과 같습니다.
- 1편: 분산학습과 집합통신
- 2편: 분산학습 대표 유형 (DP, MP, PP, Zero Infinity…)
- 3편: 분산학습 테크닉과 디버깅 노하우
학습 트렌드
분산학습이 무엇인지 알기 전에 왜 분산학습이 필요하게 되었는지 그 연유부터 알아야겠죠?
이는 DL 학습 트렌드를 찾아보면 한눈에 이해할 수 있습니다.

https://developer.nvidia.com/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/?ncid=so-link-563714&fbclid=IwAR04abX43QGzmZJBtef62NGq3MdDkgBVDeDG8iNm3cTU4OSRPdJFdCVrRo0#cid=dl20_so-link_en-us 해당 그래프는 2018년부터 2022년 최근까지 좋은 성능을 보인 Language 모델의 크기(모델이 가진 파라미터 수로 판단합니다)를 보여줍니다. 해가 지날수록 모델이 점차 커져서 2022년 NVIDIA에서 새롭게 선보인 Megatron-Turing NLG의 모델 크기는 530B에 도달하죠. 이는 Language 영역에서만 일어나는 일이 아닙니다.
아래는 2019년 구글에서 발표한 논문에서 발췌한 그림으로, Image 데이터 모델의 파라미터 수와 정확도(ImageNet을 기반으로 측정했네요)를 보여주고 있습니다. 우리는 쉽게 '모델을 구성하는 파라미터 수'가 늘어갈수록 '정확도'도 같이 높아지는 모습을 확인할 수 있습니다.

https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html 이처럼 해가 지날수록 연구자들은 더 높은 정확도를 위해 학습 파라미터 수를 점차 늘리는 액션을 취하고 있습니다. 사실 모델 크기 뿐만 아니라 모델에 학습하는 데이터셋의 크기도 점차 늘어나고 있습니다. 큰 학회의 최신 논문에서는 더이상 초기 MNIST 데이터셋을 성능 측정 지표로 삼고 있지 않죠.
분산학습은 언제 필요한가
이런 트렌드를 놓치지 않고 점점 커지는 파라미터 수와 데이터셋을 감당하기 위해서 연구자들은 보다 많은 GPU 자원을 필요로 하게 되었습니다. 더이상 GPU 1장(single node, single gpu), 더 나아가 최대 8장의 GPU(single node, multi gpu)가 붙은 서버 한 대로는 큰 모델과 데이터를 학습하기가 어려웠습니다. 이를 해결하기 위해 GPU가 붙은 서버 여러 대를 동시에 사용하여 학습하는 분산학습(multi-node training)이 등장하게 되었습니다.
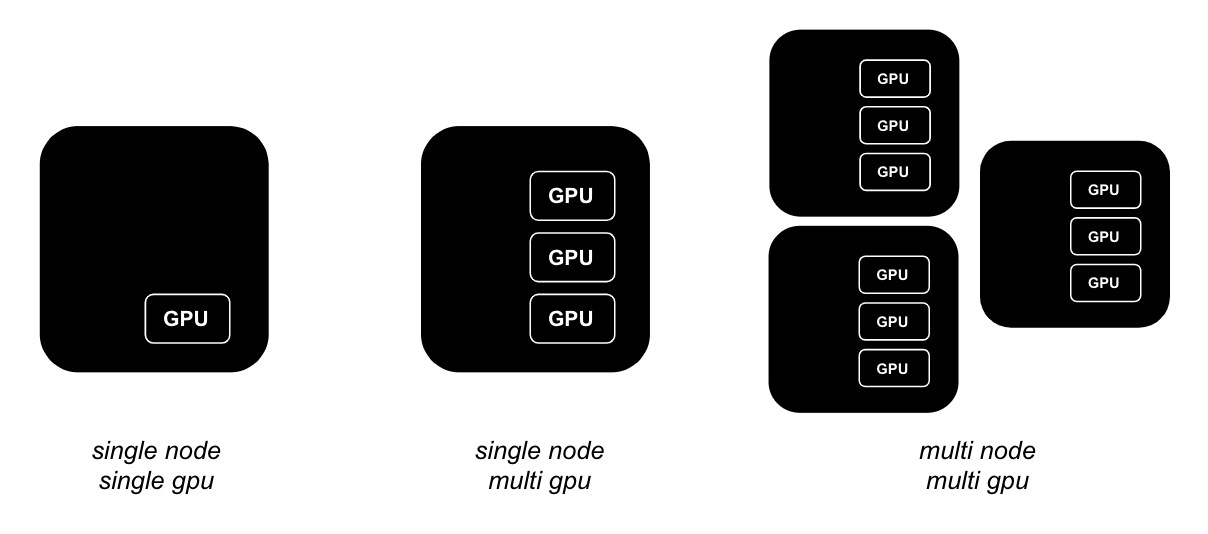
그렇다면 분산학습이 항상 좋은 방법일까요? 그렇지는 않습니다. 분산학습은 서버 내 통신을 넘어서 여러 서버가 서로 학습 결과를 계속 주고받을 수 있어야 하기 때문에 네트워크 통신이 굉장히 중요합니다. 서버 간 통신이 충분히 뒷받쳐 주지 않으면 오히려 GPU가 다른 서버의 GPU 학습 결과를 전달받기까지 기다리는 유휴 시간이 길어지면서 오히려 학습 속도가 저하될 수 있습니다. 따라서 모델의 학습 크기가 더이상 서버 한대로 감당하기 어렵거나 IB(InfiniBand)와 같은 대규모 딥러닝 클러스터에 적합한 네트워크 구성을 갖추었을 때 분산학습의 진가가 더 드러날 수 있습니다.
분산학습의 기본 흐름
분산학습에서 모델 학습과 서버 간 통신이 어떻게 어우러지는지 조금 더 살펴보도록 하겠습니다.
일반적으로 신경망(Neural Network)을 베이스로 하는 딥러닝 모델들은 다음과 같은 식을 가진 뉴런(Neuron)들로 구성되어 있습니다.

Neuron 기본 예시 물론 뉴런에 많은 변형들이 존재하지만, 기본적으로 학습을 한다는 것은 정답에 적합한 weight(위 식에서 w1, w2..)를 찾아가는 것을 일컫습니다.
다음과 같은 순서의 학습 과정을 계속 반복합니다.
- [Forward] 현재 모델의 weight를 기반으로 결과값을 계산
- [Loss] 1번의 모델 결과값과 정답 간의 차이를 계산
- [Backward] 2번의 오차를 기반으로 각 뉴런의 weight들마다 gradient를 계산
- [Update] 3번의 gradient로 모든 weight를 업데이트
- 이후 1~4를 반복
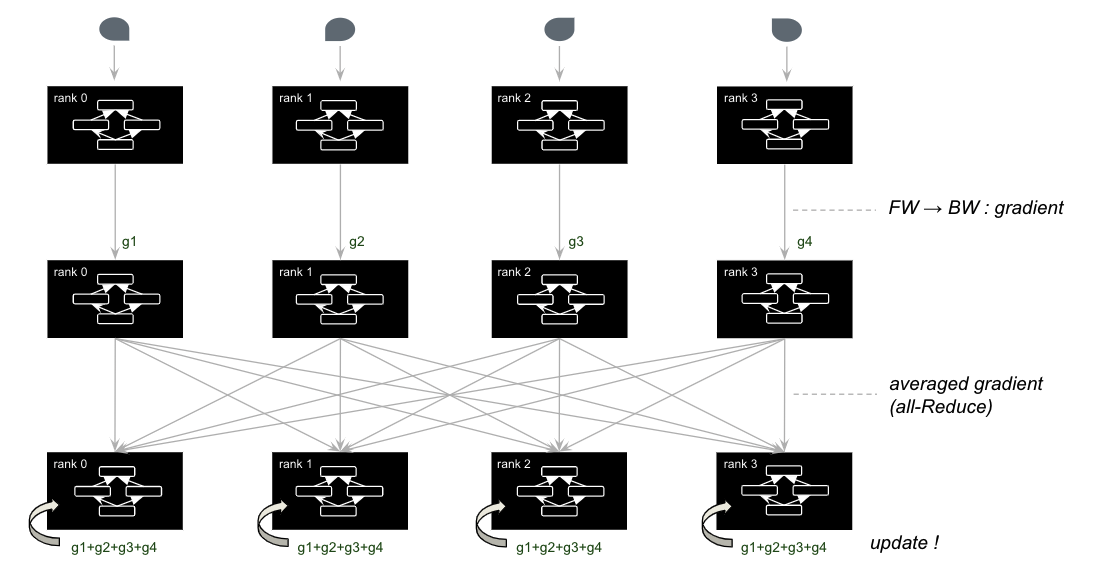
그런데 분산학습은 1~3의 과정이 각 서버마다 개별적으로 이뤄집니다. 이 후 다시 설명하겠지만 분산학습은 학습을 여러 서버에 나눠서 진행하는 것이고, 그 방식에 따라 데이터를 나누거나 모델을 나눠서 학습하게 됩니다. 어떤 방식이건 각 서버는 3의 결과로 모두 다른 Gradient 결과값을 가지고 있습니다. 따라서 4번처럼 모델을 업데이트하기 위해서는 이 결과값을 한데로 모아 계산한 Averaged Gradient로 weight를 수정해야 합니다.
아래는 서버마다 데이터를 나누어 학습하는 Data Parallelism 에서 학습이 진행되는 과정을 단순하게 도식화한 그림입니다. 맨 위의 물방울 모양은 학습 데이터입니다. 각 데이터는 서버마다 전달되고 서버내 GPU가 NN학습을 진행하며 Gradient를 계산합니다. 계산한 Gradient는 모두 모아져 평균을 계산합니다. 그리고 이 Averaged Gradient들로 각 서버가 weight를 업데이트하게 됩니다. 참고로 우리는 Data Parallelism의 단편적인 예시만 보았지만 사실 Averaged Gradient를 계산하기 이전에도 서버간 학습 결과를 싱크하는 경우가 존재합니다. (Synchronized Batch Normalization)
MPI (Message Passing Interface)
각 서버로부터 Gradient를 합산해오기 위해 일반적으로 All-Reduce 방식을 이용합니다. All-Reduce는 간단히 말해 각 지점으로부터 값을 모두 가져와 합산한 다음 이를 다시 모두에게 돌려주는 통신 방식입니다. 역시 간단히 용어로만 설명하면 이 개념이 직접 와닿지 않겠죠? 프로세스 간 통신에 대해서도 조금 더 파해쳐 봅시다.
지금까지 서버로 단순하게 표현했지만, 사실 서버보다는 서버 내 GPU 그리고 좀 더 명확하게는 각 GPU를 점유한 프로세스(process)가 개별적으로 연산을 수행한다고 말할 수 있습니다. 그리고 All-Reduce는 이렇게 서로 다른 프로세스들이 각자의 데이터를 교환하는 여러 방식 중 하나입니다. 이 방식은 어디서 정의한 걸까요? 바로 MPI(Message Passing Interface)입니다.
MPI는 분산 및 병렬 프로그래밍 환경에서 각 프로세스의 정보 교환에 대해 기술한 표준입니다. 프로세스 내에서 자원을 공유하는 쓰레드와 달리 프로세스들은 서로의 자원을 공유하지 않습니다. 따라서 프로세스들이 작업한 결과들을 서로 공유하기 위해서는 송,수신 방식에 대한 정의가 필요합니다. MPI는 '송신자, 수신자, 데이터, 데이터 크기 및 공간 정보' 등을 Message로 담고 여기에 메시지 구분을 위한 고유번호인 Tag를 붙여 다른 프로세스에 전달하는 방식(Passing)을 정의하였습니다.
MPI는 1994년 첫 표준이 마련된 후 최근 2015년(MPI-3)까지 지속적으로 업그레이드가 되고 있습니다. 이 방식은 C++이나 Python 등 어떤 언어로든 구현될 수 있으며, 대표적인 MPI 구현체로 openMPI, MPICH, MVAPICH 등이 존재합니다. 이외에도 GPU 클러스터에 특화된 집합 통신 라이브러리로 NVIDIA에서 개발한 NCCL도 있습니다. NCCL이 GPU 클러스터에서 우수한 통신 성능을 보이지만, 초기 구현틀을 잡은 것이 MPI라 MPI위주로 언급합니다.
조금 더 첨언하면, 분산학습이 수행되는 대부분의 환경은 충분한 하드웨어 스펙으로 구성된 고성능 컴퓨팅 즉, HPC(High Performance Computing) 환경으로 이루어졌습니다. 그리고 HPC 환경에서 각 프로세스가 통신하는 대표적인 통신방식으로 MPI를 언급하곤 합니다.
Collective Communication
다시 본론으로 들어가서 이야기의 시작점인 All-Reduce가 무엇이기에 MPI를 설명했는지 얘기해보도록 하겠습니다. MPI는 프로세스간 Message Passing 방식을 정의했다고 했습니다. 프로세스가 다른 프로세스와 1:1로 통신하는 Point-to-Point communication에서는 송수신이 명확하지만, 여러 프로세스들이 1:N 또는 N:N으로 통신하는 Collective Communication(집합 통신)은 다양한 유형이 존재합니다.
Collective Communcation 의 여러 종류는 그림으로 쉽게 이해될 수 있습니다. 아래는 Pytorch Tutorial 에서 Collective Communication 을 소개하는 그림입니다. (MPI tutorial 에서 제공하는 그림이 있었습니다만, 아래 그림이 훨씬 더 직관적으로 잘 그렸다고 생각하기 때문에 이 그림을 reference로 실어봅니다) MPI에서는 각 프로세스를 Rank로 표현하기 때문에 그림의 Rank 하나하나를 각각 프로세스로 이해하면 됩니다.

https://tutorials.pytorch.kr/intermediate/dist_tuto.html 먼저 1:N 통신에서는 Scatter, Gather, Reduce, Broadcast 가 존재합니다. Scatter는 각 Rank의 결과값을 다른 모든 Rank에게 분할해서 전달하는 것이고, Gather는 반대로 분할되어 있는 결과들을 하나로 모으는 것입니다. Reduce는 Gather에서 한단계 더 나아가서 값을 모두 모으고 합산하는 방식이며, 마지막으로 Boradcast는 모든 Rank에게 동일한 결과를 전달하는 방식입니다.
N:N 통신에는 All-Reduce와 All-Gather가 있습니다. All-Gather는 각 Rank별로 나눠진 결과값을 모든 Rank에 동일하게 전달하는 방식입니다. 그리고 All-Reduce는 Rank의 결과를 모두 합산한 값을 모든 Rank에 동일하게 전달하는 방식입니다.
분산학습에서 GPU를 점유하는 프로세스들 즉, 각 Rank의 Gradient 값은 모두 합산해서 평균을 낸 후 다시 모든 Rank에게 전달될 필요가 있습니다. 그래서 분산학습에서 모델 업데이트를 위해 Gradient를 공유하는 방식은 All-Reduce 가 필수적이라고 말할 수 있겠습니다.
Ring-AllReduce
마지막으로 Ring-AllReduce 만 설명하고 마무리하겠습니다. All-Reduce를 실제로 구현하기 위해 다양한 알고리즘이 존재하는데, 그 중 현재 가장 많이 사용되는 방식이 Ring-AllReduce 입니다. 모든 값을 합산하고 다시 모두에게 전달해야하는 All-Reduce는 모든 서버와 최소한의 통신으로 합산과 전달이 동시에 이뤄져야 합니다. Ring-AllReduce는 Ring 형태로 프로세스들이 결과값을 전달합니다.

https://tech.preferred.jp/en/blog/technologies-behind-distributed-deep-learning-allreduce/ 각 스텝을 설명하면 다음과 같습니다.
- 각 프로세스는 자체 배열을 집합 통신에 참여하는 P개의 chunk(하위 배열)로 나눕니다.
- 첫 통신에서는 각 프로세스가 자신의 번호에 해당하는 chunk를 다음 프로세스로 전달합니다.
- 이후부터는 자신이 전달받은 번호의 chunk와 자신의 가진 같은 번호의 chunk를 다음 프로세스로 전달합니다.
- 2번의 첫 통신을 포함하여 P-1번의 통신 이후에는 각 번호의 모든 chunk를 동일하게 전달받을 수 있습니다.
그림에서 4개의 프로세스가 통신에 참여하니 이에 맞추어 다시 적어보면 이해가 더 쉬울 것입니다.
- 각 프로세스가 자신의 배열을 총 4개의 chunk로 나눕니다.
- 첫 통신에서는 1번 프로세스는 자신의 1번 조각을 2번 프로세스로 송신합니다.
1번 프로세스는 4번 프로세스가 전달한 chunk 4를 전달받습니다. - 두번째 통신에서 1번 프로세스는 4번 프로세스가 전달한 chunk 4와 자신이 가진 chunk 4를 합해 2번 프로세스에게 송신합니다. 동시에 1번 프로세스는 4번 프로세스로부터 chunk 3(3번 프로세스의 chunk 3가 포함된)를 전달받습니다.
세번째 통신에서 1번 프로세스는 3, 4번 프로세스가 전달한 chunk 3에 자신의 chunk 3까지 더해 2번 프로세스에게 전달합니다. - 세번째 통신의 결과로 2번 프로세스는 1번,3번,4번 프로세스의 chunk 3을 전달받게 되고, 자신의 chunk 3까지 합해 완벽한 chunk 3 배열을 손에 얻게 됩니다.
마무리
오늘은 분산학습의 등장 배경, 그리고 분산학습의 Gradient 계산 과정과 그 과정에서 이뤄지신 통신 방식까지 살펴 보았습니다. 다음 쳅터에서는 분산학습의 다양한 유형을 소개하면서 좀 더 깊이 들어가보도록 하겠습니다.
'AI > distributed' 카테고리의 다른 글
분산학습 대표 유형: DP vs MP (1) 2022.06.12