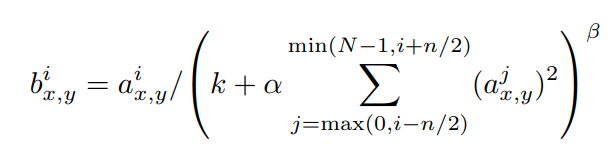-
Convolution Neural Network History - AlexNetAI/concept 2020. 6. 7. 22:27
convolution layer를 근간으로 image와 같은 다채널 데이터를 처리하는데 좋은 Neural Network를 순서대로 정리해보자
다양하고 좋은 CNN이 많지만 대표적인 Network들을
1)아키텍처 구조와 2)대표적인 특징점들을 기준으로 설명하겠다
순서는 다음과 같다.
AlexNet -> VggNet -> GoogleNet -> ResNet -> DenseNet ->
ShuffleNet -> MobileNet -> SENet -> CondenseNet -> NASNet
첫번째는 AlexNet이다.
[1] AlexNet
Alexnet은 CNN네트워크를 구성할 때 지금까지 우리가 기본적으로 사용하는 테크닉들을 정착화시킨 논문이다.

https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf (1) ReLU Nonlinearity
이전 LeNet 논문에서만 해도 tanh함수가 standard하게 사용되었는데 이를 Relu로 변경하였다.
저자는 ReLU로 학습 시, tanh와 동일한 정확도를 유지하면서 학습속도는 약 6배 정도 빠르다고 설명한다.
이는 tanh는 -1에서 1사이의 값을 리턴하지만, ReLU는 양수의 모든 값을 리턴할 수 있기 때문에
backward시 ReLU가 더 큰 값으로 업데이트가 가능하기 떄문이다.


(2) Overlapping Pooling
지금은 Pooling이라하면 자연스럽게 pooling size와 stride를 지정하지만, 이전 논문까지만 해도 겹쳐서 pooling을 시도한 적이 없었다.
(3) Dropout
AlexNet의 가장 대표적인 기법은 바로 Dropout이다. 훈련중에 일정한 확률로 해당 뉴런의 결과를 0으로 셋팅하여 학습을 forward-backward가 진행되지 않도록 하는 기법이다. regularization에 도움을 주어 과적합을 방지하고, 뉴런들이 서로 동조(co-adaption)되는 현상을 방지하여 학습 데이터에 대해 강건한 모델을 만들 수 있다.
추가로 AlexNet에서는 과적합을 방지하기 위해서 data-augmentation 기법도 사용하였다.
(4) Local Response Normalization (LRN)
지금은 Batch Normalization이 일반적으로 사용되고 있어 더이상 사용하지는 않는 기법이다. Convolution으로 이미지 데이터를 스캔할 때 특정 픽셀값이 다른 픽셀에 비해 지나치게 높은 값을 가지고 있어 주변에 큰 영향력을 끼치는 것을 자제시키는 일반화 방법의 하나이다. 이는 tanh가 아닌 ReLU activation function(y=max(0,x))을 사용할 떄 지나치게 큰 값이 통과되어 발생하는 부작용을 줄이기 위해 사용된다. 식을 보면 (x, y) 위치 근처의 activity 합계값을 분모로 보낸다.